AWS による docker コンテナのオーケストレーションサービスである Amazon ECS / Fargate のヘルスチェックの挙動について調査する機会がありましたのでアウトプットしておきたいと思います。
前提として Fargate で ECS のサービスとして、ロードバランサーは Application Load Balancer(ALB)を利用して実行するケースで調査しました。網羅的ではない点、ご了承ください。
ECS におけるヘルスチェック
さて、ECS でサービスを実行する上で、いわゆる「ヘルスチェック」は2種類あります。
- Elastic Load Balancer(今回は ALB)に関連付けられる Target Group によるヘルスチェック
- タスク定義のコンテナに対して実行する docker によるヘルスチェック(参考 : docker ドキュメント, AWS ドキュメント )
今回はこれらをそれぞれ「ELB ヘルスチェック」と「コンテナヘルスチェック」としてこれらのヘルスチェックによるタスクの挙動について調査しました(「ELB ヘルスチェックは正しくは「Target Group ヘルスチェック」ですが便宜上このように表現します)。
アーキテクチャ
以下のようなアーキテクチャで調査しました。
タスクには Flask で作成したシンプルなアプリを実行しており、任意のステータスコードが返せるようにしています。また、あとで確認しやすいよう ECS イベントを Elasticsearch に送っています。

ケース 1 : ELB からのヘルスチェックには正常、コンテナヘルスチェックは失敗
まずはじめに、ELB ヘルスチェックでは healthy ですが、コンテナヘルスチェックでは UNHEALTHY という時にどのような挙動となるか確認しました。
各ヘルスチェックのパラメータは以下の通りです。
-
ELB ヘルスチェック : 常にステータスコード 200 を返すように設定
- パス :
/elb - 間隔 : 30 sec
- タイムアウト : 5 sec
- 正常のしきい値 : 5
- 非正常のしきい値 : 2
- 猶予期間 : 3600 sec (ECS のサービスで設定)
- パス :
-
コンテナヘルスチェック : 常にステータスコード 500 を返すように設定
- チェックコマンド :
curl -f http://localhost:8080/docker || exit 1 - 間隔 : 30 sec
- タイムアウト : 5 sec
- 開始期間 : 180 sec
- 再試行 : 10
- チェックコマンド :
アプリ側でアクセスの都度 CloudWatch Logs にログを出しておくようにしておきました。以下の図のとおり、ELB ヘルスチェックもコンテナヘルスチェックもタスクがデプロイされると 猶予期間 や 開始期間 に関わらずすぐにヘルスチェックが実行されます。
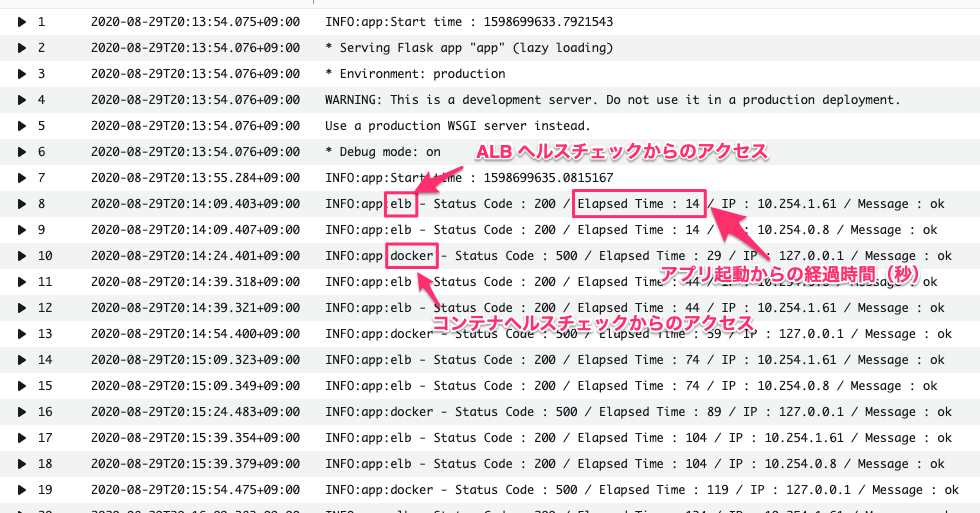
結果 : ケース 1 ではどのような挙動となるか
コンテナヘルスチェックとしてはステータスコードを 500 で返すようにしているのでデプロイ後 開始期間 + 間隔 x 再施行 後(8分程度後)、コンテナのヘルスステータスは以下のイベントメッセージと共に UNKNOWN から UNHEALTHY になります。
Task failed container health checks
しかし、ELB ヘルスチェックが 3600 秒と長めに取ってあるのですぐにタスクの置き換えが実行されることはないようです。ELB ヘルスチェックは常に healthy という状況ですが、 ELB ヘルスチェックの猶予期間が経過するとタスクの置き換えが ECS サービススケジューラにより実行されます。
下の図は ECS イベントを Elasticsearch(+ Kibana)で出力した図です。20:12 頃デプロイし、ELB ヘルスチェックの猶予期間(3600秒)が経過した、21:14頃にタスクの置き換えが実行されているのがわかります(新しい taskArn のプロビジョニングが始まっている)。
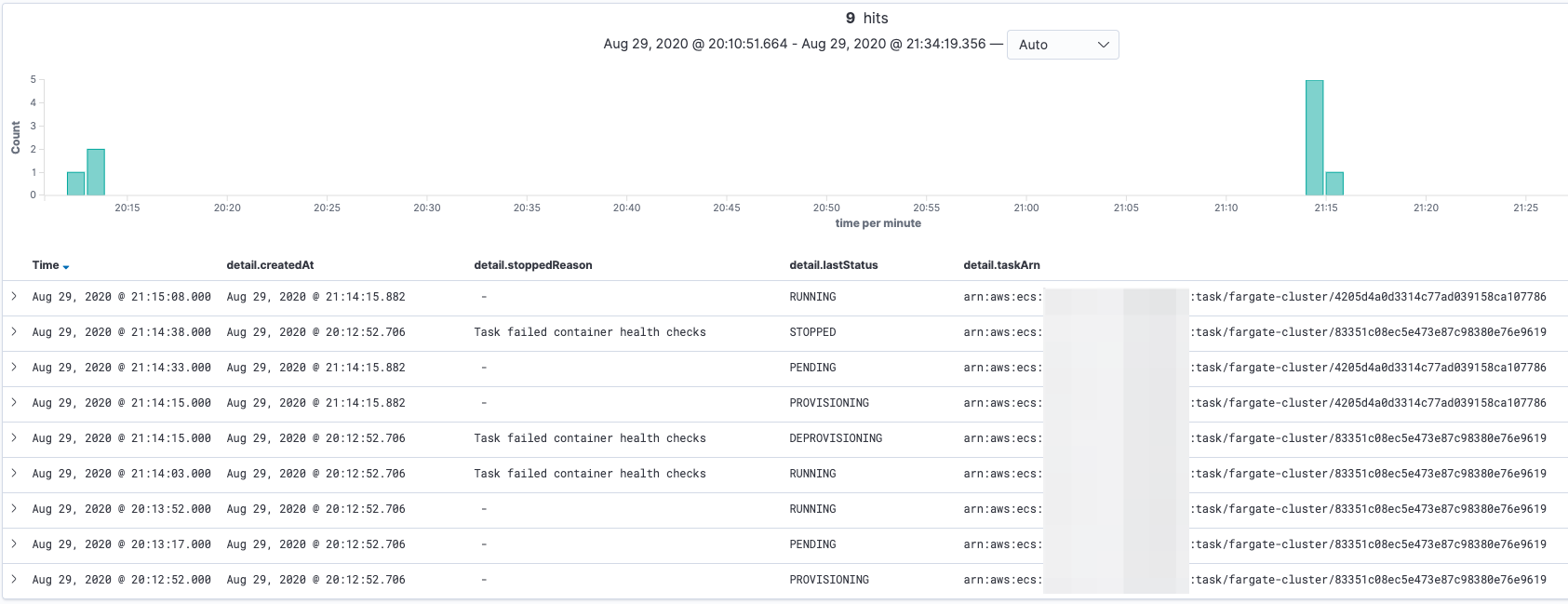
ケース 1 まとめ
ケース 1 での時系列をまとめると以下のようになります。

ケース 1 での結果をまとめると、
「ELB ヘルスチェックの猶予期間が経過すると、ELB のヘルスチェック結果が healthy であってもコンテナヘルスチェックのステータスが UNHEALTHY なタスクは置き換えられる」 ということがわかりました。
ところで、ELB ヘルスチェックの猶予期間が経過するとすぐに置き換えが始まるのか?、ELB ヘルスチェックで 非正常のしきい値 の回数分ヘルスチェックを行うのか? このケースでは ELB ヘルスチェックの 間隔 と 非正常のしきい値 がトータル1分ほどしかなかったので、ちょっとわかりづらいです。次のケースで ELB ヘルスチェックでの失敗までの期間が長くなるようにして試してみます。
ケース 2 : UNHEALTHY なタスクがあった場合に、ELB のヘルスチェックはすぐにタスクを置き換えるのか、非正常のしきい値を超えるまでチェックを繰り返すのか
さて、今度は ELB ヘルスチェックが猶予期間を経過したのち、タスクのヘルスチェックステータスが UNHEALTHY だった場合、即座にタスクの置き換えが実行されるのか、ELB のヘルスチェックが 非正常のしきい値 を超えるまでタスクの置き換えは実行されないのか確認してみたいと思います。ただし、このケースでも ELB のヘルスチェックは常に healthy であるようにします。
各ヘルスチェックのパラメータは以下の通りで、ELB ヘルスチェックの 間隔 と 非正常のしきい値 を大きくし、 unhealthy になるまで時間がかかるようにします。(ケース1では猶予期間を長く取りすぎたので 900sec に縮めました。。。)コンテナヘルスチェックのところはそのままです。
-
ELB ヘルスチェック : 常にステータスコード 200 を返すように設定(常に
healthy)- パス :
/elb - 間隔 : 300 sec
- タイムアウト : 5 sec
- 正常のしきい値 : 5
- 非正常のしきい値 : 10
- 猶予期間 : 900 sec (ECS のサービスで設定)
- パス :
-
コンテナヘルスチェック : 常にステータスコード 500 を返すように設定(ケース1と同じ)
- チェックコマンド :
curl -f http://localhost:8080/docker || exit 1 - 間隔 : 30 sec
- タイムアウト : 5 sec
- 開始期間 : 180 sec
- 再試行 : 10
- チェックコマンド :
結果 : ケース 2 ではどのような挙動となるか
ケース 2 での結果としては、ELB ヘルスチェックの猶予期間が経過すると即座に、コンテナヘルスチェックステータスが UNHEALTHY なタスクは置き換えが実行されました。
以下は CloudWatch Logs に出力したアクセスログですが、ELB ヘルスチェックの 猶予期間 で設定した 900 秒を経過するとタスク ID が変わっている(タスクが置き換えられている)のがわかります。
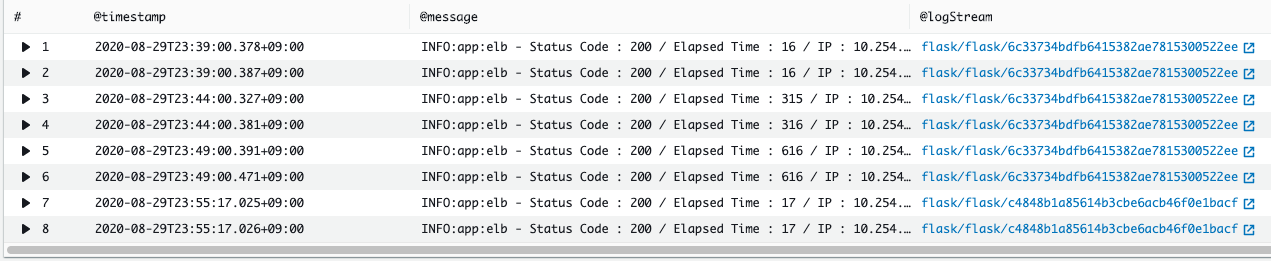
以下は、ECS イベントを Elasticsearch でみてみたものです。23:38:41 にデプロイから RUNNING になったタスクが約 900 秒後の 23:53:45 にコンテナヘルスチェックに失敗していることが報告され、タスクの置き換えが開始しているのがわかります。
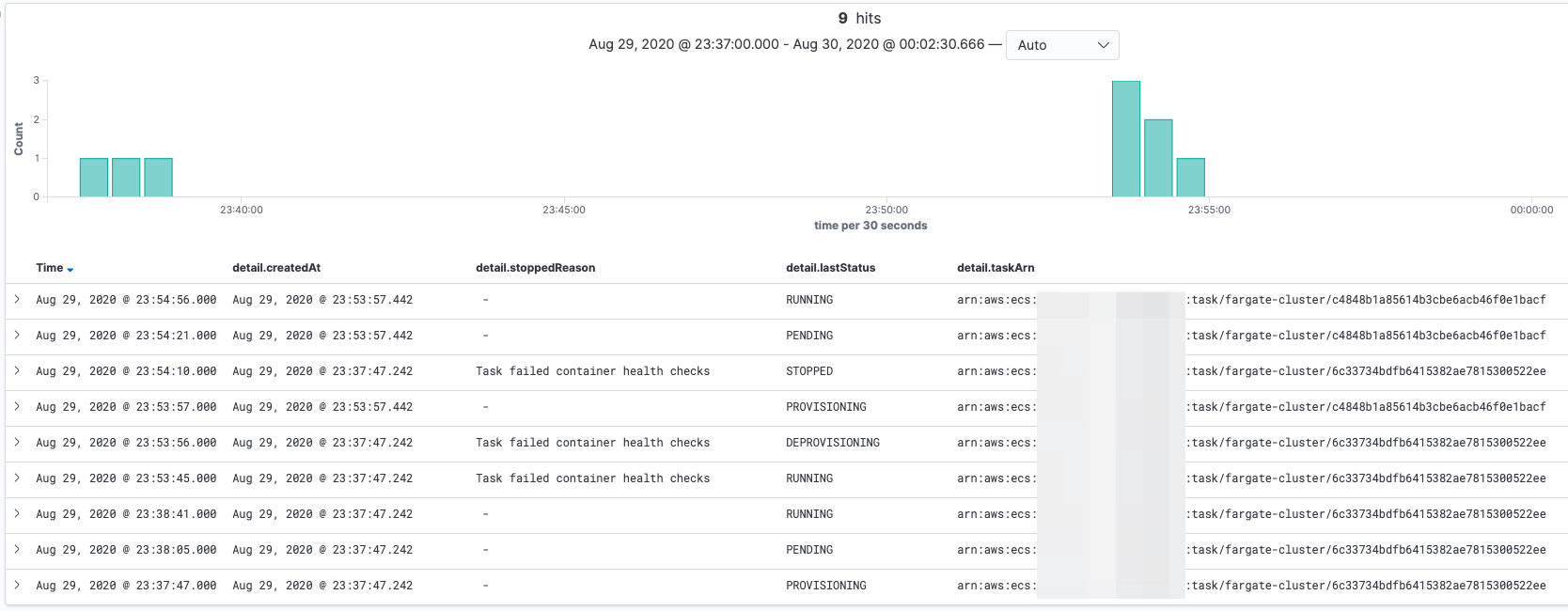
ケース 2 まとめ
ケース 2 での時系列をまとめると(ケース 1 とほとんど変わらないのですが)、以下のようになります。

ケース 2 の結果をまとめると、
「ELB ヘルスチェックの猶予期間が経過した時点でコンテナのヘルスチェックステータスが UNHEALTHY の場合、即座にタスクの置き換えが実行される。」 というのがわかります。
ケース 3 : ELB ヘルスチェックは即座に開始、コンテナヘルスチェックの 開始期間 の間に UNHEALTHY になる場合
コンテナのヘルスチェックステータスが UNHEALTHY で、ELB のヘルスチェックの 猶予期間 が経過していれば即座にタスクの置き換えが実行されることがわかりました。それでは、コンテナヘルスチェックの 開始期間 中に UNHEALTHY となるような状況であればどうなるでしょうか?(※後ほど結果で示しますが、この「 開始期間 中に UNHEALTHY となる」という表現は誤っています。)
ドキュメント では 開始期間 ( startPeriod )は以下のように説明されています。
再試行の最大回数でヘルスチェックが失敗とカウントされる前に、コンテナにブートストラップする時間を提供する猶予期間のオプションです。0〜300 秒を指定できます。デフォルトでは startPeriod は無効となっています。
これだけではちょっと判断がつかないので、以下のように ELB ヘルスチェックの 猶予期間 を短く、コンテナヘルスチェックの 開始期間 を長めにしたパラメータで試してみたいと思います( 開始期間 を待たずに UNHEALTHY なタスクを置き換えてしまうかどうかを確認してみたいと思います)。
ただし、このケースでも ELB のヘルスチェックは常に healthy であるようにします。
-
ELB ヘルスチェック : 常にステータスコード 200 を返すように設定(常に
healthy)- パス :
/elb - 間隔 : 10 sec
- タイムアウト : 5 sec
- 正常の閾値 : 5
- 非正常の閾値 : 2
- 猶予期間 : 0 sec (ECS のサービスで設定)
- パス :
-
コンテナヘルスチェック : 常にステータスコード 500 を返すように設定
- 間隔 : 30 sec
- タイムアウト : 5sec
- 開始期間 : 300 sec
- 再試行 : 2
結果 : ケース 3 ではどのような挙動となるか
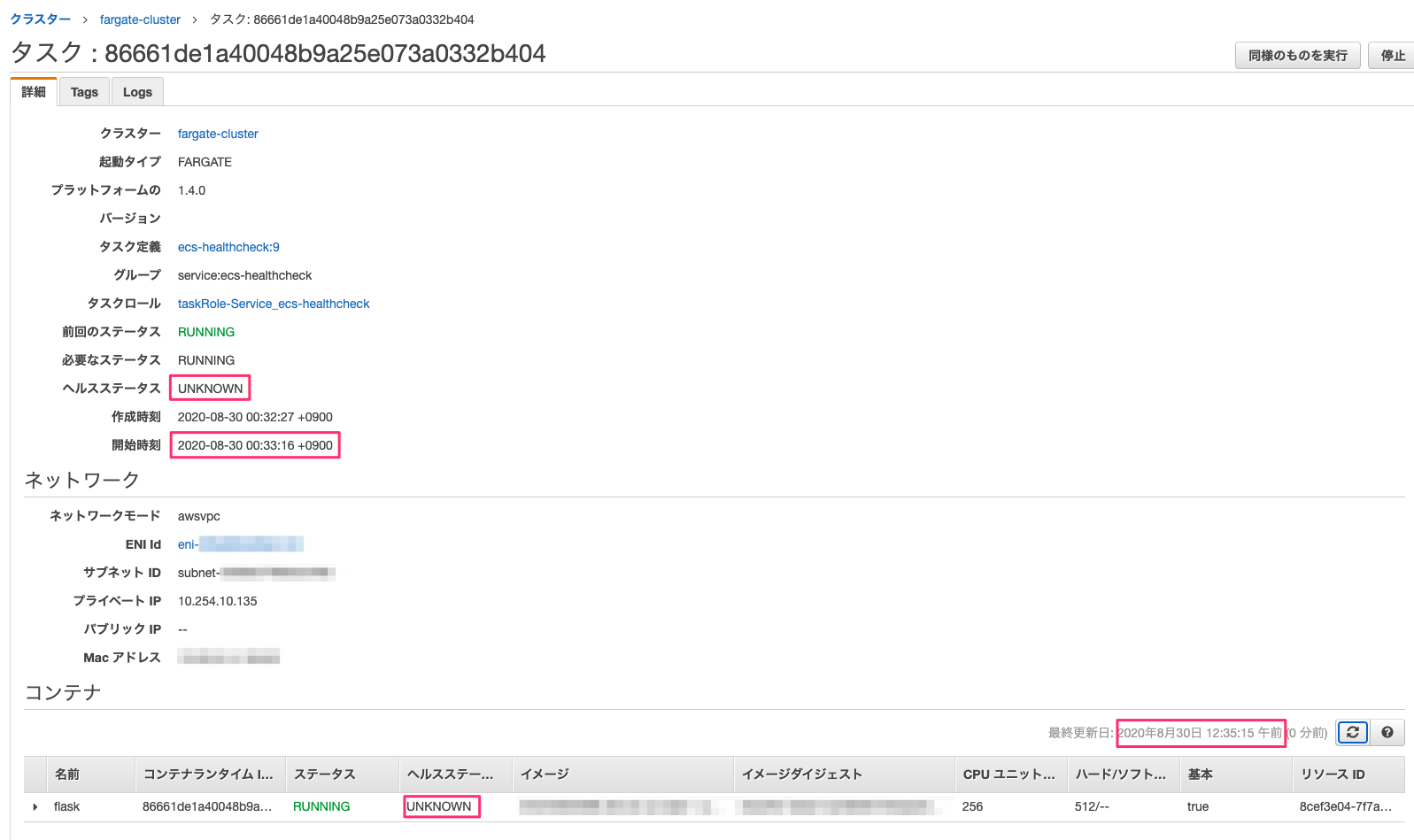
ケース 3 では、コンテナのヘルスチェックステータスとして、1分ほど( 間隔 x 再試行 )で UNHEALTHY になるというわけではなく、 開始期間 の間は UNKNOWN に維持されます。以下の図は、00:33:16 に開始したタスクの 00:35:15 時点でのステータスをみてみたものです。赤枠で強調している通り、 UNKNOWN としてステータスを維持しています。
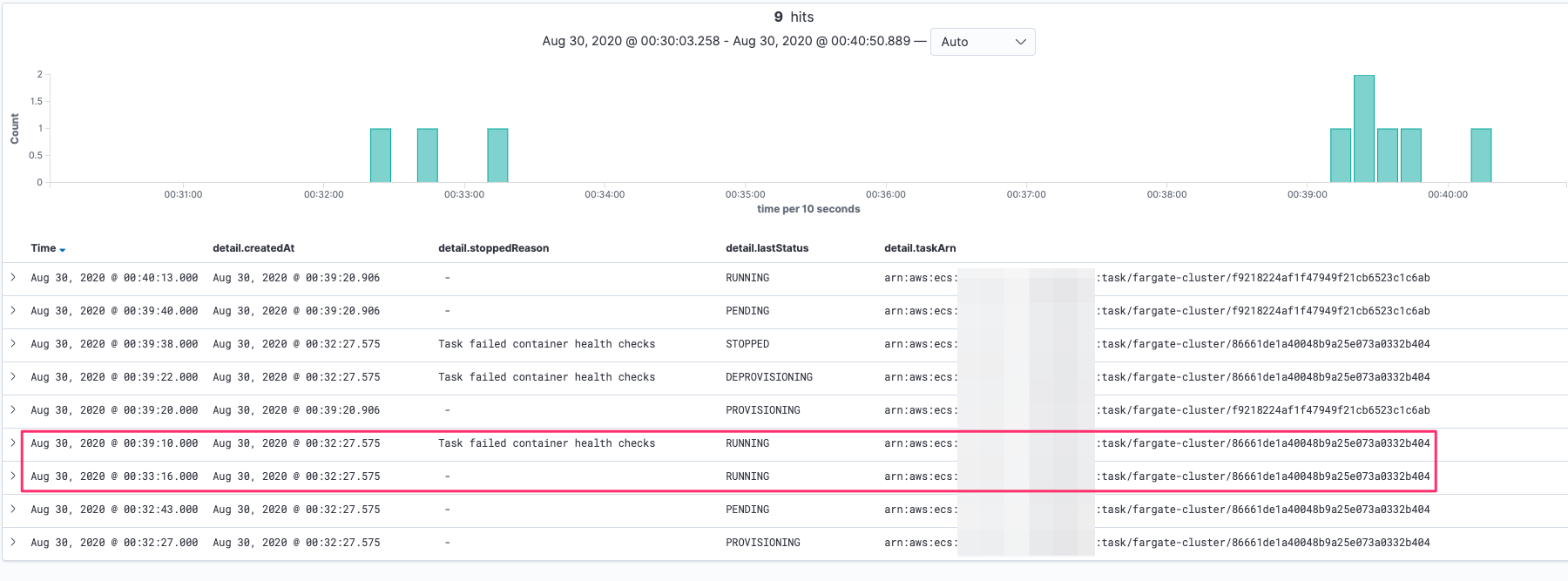
また、以下の図は ECS イベントを Elasticsearch で表示したものです。00:33:16 に RUNNING ステータスになったタスクは約 6 分後の 00:39:10 にコンテナのヘルスチェックに失敗したことが報告されています。これはコンテナのヘルスチェックステータスが「 開始期間(300 sec) + 間隔(30 sec) x 再試行(2 回) の間 UNKNOWN に維持されているから」、ということがわかるかと思います。
ケース 3 まとめ
ケース 3 での時系列をまとめると、以下のようになります。

ケース 3 の結果をまとめると、
コンテナのヘルスチェックは 開始期間 の間 UNKNOWN を維持する。
開始期間 経過後、ヘルスチェックを行い(このケースで 30秒間隔 2回実行後)、 UNHEALTHY へ。そしてすぐタスクの置き換えが実行される。
ケース 4 : 開始期間 の間に ELB ヘルスチェックにより unhealthy になった場合
ケース 3 はタスクのヘルスチェックステータスが UNKNOWN 、ELB によるヘルスチェックステータスが healthy であった場合タスクの置き換えは実行されない、という考えてみれば普通の挙動です。
では最後のケースとして、タスクのヘルスチェックステータスが 開始期間 中、すなわちケース 3 と同様 UNKNOWN であるときに、ELB によるヘルスチェックが unhealty となるようなケースを確認してみたいと思います。
ケース 1 - 3 までは、ELB のヘルスチェックステータスは常に healthy でしたが、最後のケースでは unhealthy となるようにします。
-
ELB ヘルスチェック : 常にステータスコード 500 を返すように設定(常に
unhealthy)- パス :
/elb - 間隔 : 10 sec
- タイムアウト : 5 sec
- 正常の閾値 : 5
- 非正常の閾値 : 2
- 猶予期間 : 0 sec (ECS のサービスで設定)
- パス :
-
コンテナヘルスチェック : しばらく
UNKNOWNとなるように設定- チェックコマンド :
curl -f http://localhost:8080/docker || exit 1 - 間隔 : 60sec
- タイムアウト : 5sec
- 開始期間 : 300sec
- 再試行 : 10
- チェックコマンド :
結果 : ケース 4 ではどのような挙動となるか
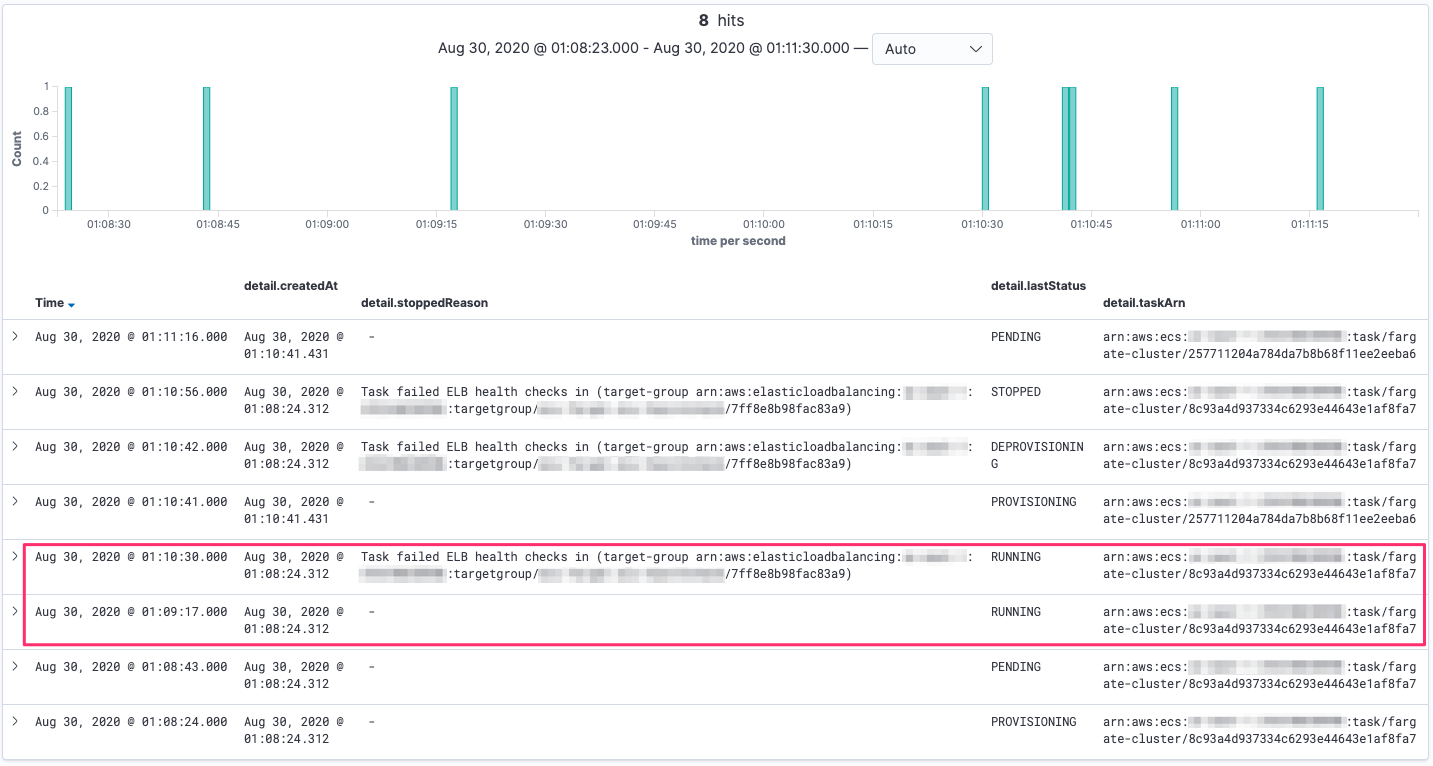
以下の図は ECS イベントを Elasticsearch で表示したものです。01:09:17 に RUNNING になったタスクが 01:10:30 には ELB のヘルスチェックにより非正常であることが報告され、タスクの置き換えの開始につながっています。つまりはコンテナヘルスチェックのステータスが UNKNOWN の時、ELB のヘルスチェック結果が unhealthy となると即座にタスクの置き換えが実行されます。ELB のヘルスチェックに失敗した時の停止理由として以下のメッセージが出力されます。
Task failed ELB health checks in (target-group arn:aws:elasticloadbalancing:<REGION>:<AWS_ACCOUNT>:targetgroup/<TARGET_GROUP_NAME>/<UID>)
振り返ってみれば、コンテナのヘルスチェックを設定せず、ELB のヘルスチェックのみ使うケースと同じです。。。
ケース 4 まとめ
ケース 4 での時系列をまとめると、以下のようになります。

ケース 4 の結果をまとめると、
コンテナのヘルスチェックステータスにかかわらず、ELB のヘルスチェックステータスが unhealthy となった場合は、即座にタスクの置き換えが実行される、ということになるかと思います(まぁ普通ですね・・・)。
まとめ
以上から ECS におけるヘルスチェックの挙動についてまとめると
- ELB ヘルスチェックもコンテナヘルスチェックも
猶予期間や開始期間にかかわらず、タスクのプロビジョニング後すぐに実行される - ELB ヘルスチェックの猶予期間が経過すると、ELB のヘルスチェック結果が
healthyであってもコンテナヘルスチェックのステータスがUNHEALTHYなタスクは即座に置き換えられる - コンテナのヘルスチェックステータスが
UNHEALTHYであっても、ELB のヘルスチェックが猶予期間中であれば、タスクの置き換えは実行されない - コンテナのヘルスチェックは
開始期間の間UNKNOWNを維持する - コンテナのヘルスチェックステータスにかかわらず、ELB のヘルスチェックステータスが
unhealthyになった場合は、即座にタスクの置き換えが実行される
最後に・・・
この投稿は個人的なものであり、所属組織を代表するものではありません。ご了承ください。