Amazon ECS で “タスクを再起動せずにコンテナを再起動する機能が提供” されました。これは ECS タスク内のコンテナが終了した場合に、コンテナをローカルで再起動させることができる機能で、タスクを置き換える (再デプロイする) ことなく迅速にコンテナを回復できる機能です。こちらの機能を使ってどのぐらい早く回復できるか試してみました。
モチベーション
ECS タスク内のコンテナがプロセスとして終了してしまった場合の回復手段として、タスクを新たに起動し、置き換えるのが一般的です。コンテナ定義で必須 ("essential": true) として指定されていれば、コンテナが終了すると ECS がタスクの置き換えを実行してくれます。一方、必須ではない場合 ("essential": false) は、タスクメタデータエンドポイントを利用すれば検知は可能ですが、置き換えまで実行しようとするとなかなか複雑になりそうです。
いずれにせよ、コンテナを回復するためにはタスクの置き換えが必要になり、すなわち新たにタスクを起動することになります。
新しく機能追加となった “再起動ポリシー” を使うと、コンテナの終了を検知すると、タスクとしてはそのまま、コンテナだけを起動し直してくれるのでタスクの置き換えより早く回復させることができそうです。

特に、これまで実装が複雑になりそうだった「必須ではないコンテナ」が停止してしまった時の回復手段として有用かもしれません (それなら必須にしても良いのではというのもありそうですが…)。
再起動ポリシーの設定方法
再起動ポリシーの設定はとても簡単で、タスク定義内のコンテナ定義をするところで、コンテナごとに設定していきます。
|
|
- 8行目 -
enabled: 再起動ポリシーによる再起動の有効/無効を設定します - 9行目 -
ignoredExitCodes: 再起動をせず無視する終了コードを配列で指定します。50個まで指定できます。デフォルトでは全ての終了コードを無視しない動作になります - 10行目 -
restartAttemptPeriod: 再起動を試みる前にコンテナが実行されていないといけない時間を秒単位で指定します。言い換えると、コンテナ起動後この時間内にコンテナが終了した場合は再起動されません。デフォルトは 300 秒で 60 - 1800 の間で指定できます
ちなみに restartAttemptPeriod の時間以内にコンテナが終了した場合、その時間が経過しても再起動はしてくれません。
詳細はドキュメントも参照くださいませ。
考慮事項
再起動の対象となるのは「終了したコンテナ」なので、応答性が悪かったり、ハングしているような状況では再起動してくれません。従来のヘルスチェックによるモニタリング、タスク置き換えによる回復も必要でしょう。
ドキュメントにはいくつか制限事項もあるようなので一部ピックアップしておきますと、
- ECS エージェントが切断されている時にコンテナが終了すると再起動は実行されない
- コンテナ定義で
firelensConfigurationを指定した場合、再起動ポリシーを有効にできない
ドキュメントでは firelensConfiguration を指定するコンテナ、すなわちログルータとなる Fluentd や Fluent Bit といった firelens コンテナでは有効にできないとありましたが、FluentBit のコンテナ定義で再起動ポリシーを設定しタスク定義として登録することもできましたし、タスクとしても起動することができました。さらにコンテナ終了を試してみた (execute-command から kill -15 1 をしてみた) ところ、fluent-bit コンテナは再起動してきました。とはいえ、サポートされない動作になるので注意が必要です。
その他、コンテナエージェントや Fargate プラットフォームのバージョンなどはドキュメントを参照してください。
どのぐらいの時間で再起動してくるのか
では実際どのぐらいで再起動してくるのか、実際に試してみました。いずれも Fargate で CPU アーキテクチャは ARM64、cpu: 256、memory: 512 で実行してみました。
環境設定、アプリの実装などにより結果は変わってくるかと思いますのであくまで参考程度に。
Nginx コンテナ
Nginx のコンテナで ECS Exec を使って kill -15 1 で終了させてみました。
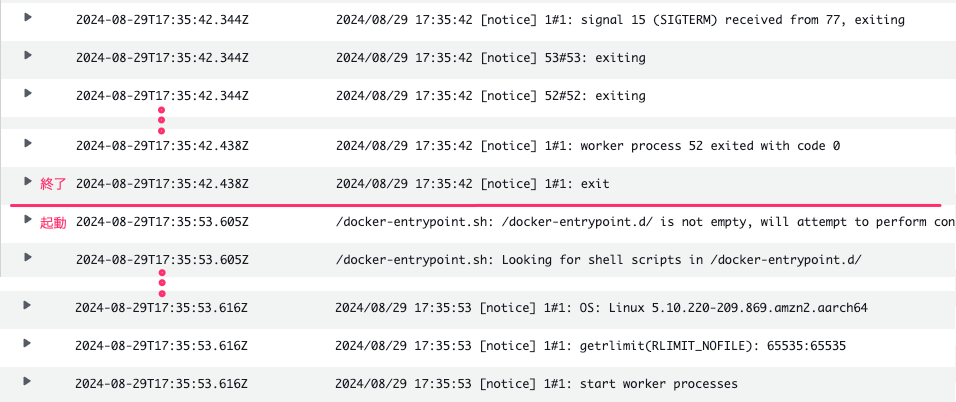
ちょっと見にくいですが、17:35:42 で終了し、17:35:53 で起動してきていますので 10秒程度で再起動しました。これぞコンテナという感じで早いですね。
Java コンテナ (Spring Boot)
次に、超シンプルな Spring Boot アプリで試してみました。ベースイメージは amazoncorretto:17 で。
|
|
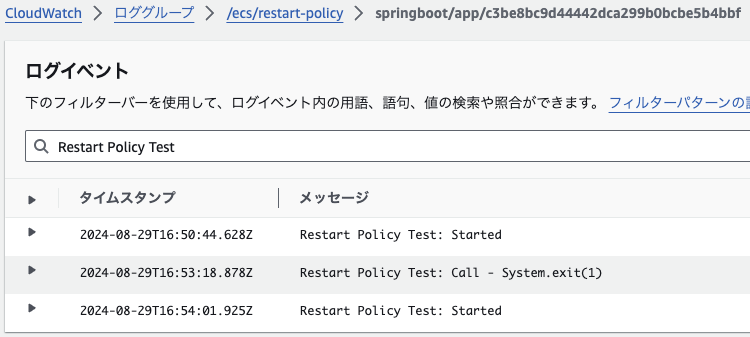
/exit?code=1 にアクセスすると終了コード 1 で Java コンテナが終了するようにしてみました。24行目の終了直前のログから再起動後の 14行目のログが出るまでの時間をみてみたいと思います。
結果としては下図の通り 43秒、何度か試してみましたが 40 - 50秒程度で回復してきてくれました。同じタスク内でのコンテナの再起動なので同一の Log Stream (つまりタスク ID は変わっていない) にログが出力されているというのもポイントです。
タスクの置き換えの場合…
再起動ポリシーを無効にし、必須コンテナ終了からのタスク置き換えを、前述の Spring Boot アプリのコンテナで試してみました。ログストリームも変わってしまうので Logs Insights から見てみます。
何度か試してみた範囲では 1分ちょっと 〜 3分と、数分以内でタスクの置き換えが完了しました。

大きな差ではないかもしれませんが、再起動ポリシーを使った方が幾分早く回復させられそうです。
使用例
基本的に終了コードが 0 以外であれば ("ignoredExitCodes": [ 0 ])、再起動するようにしておいて良いんじゃないかなと思います。
Java アプリで OutOfMemoryError が出たらコンテナを再起動する
一例ですが、Java アプリで OutOfMemoryError が出てしまった場合にとりあえず再起動をさせておきたい、という場合には Java の起動オプションに Java8u92 から使えるという -XX:+ExitOnOutOfMemoryError を指定してあげるとよさそうです。OutOfMemoryError が発生すると Java プロセスが終了し、再起動ポリシーによりコンテナを再起動することができます。
ENTRYPOINT [ "java", "-XX:+ExitOnOutOfMemoryError", "-jar", "app.jar" ]
再起動回数のモニタリング
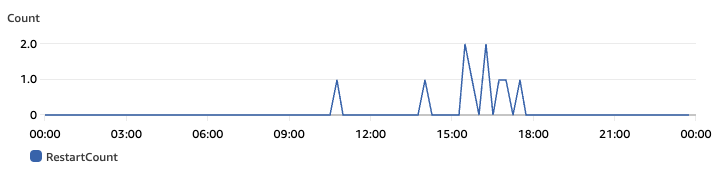
Container Insights が有効になっていれば、いずれのディメンションでも RestartCount というメトリクスで、再起動した回数をモニタリングすることができます。
ちょっと気になった点…
試している間にちょっと気になった点として、ECS Exec を利用している場合、再起動ポリシーによって再起動されたコンテナには execute-command が使えなくなってしまいました (再起動前であれば使えます)。SSM エージェントが起動していないなどの問題があるのかもしれません。今後の改善に期待ですかね。
$ aws ecs execute-command \
--cluster ${cluster_name} \
--container ${container_name} \
--interactive \
--command "/bin/bash" \
--task ${ecs_task_id}
The Session Manager plugin was installed successfully. Use the AWS CLI to start a session.
An error occurred (InvalidParameterException) when calling the ExecuteCommand operation:
The execute command failed because execute command was not enabled when the task was run
or the execute command agent isn’t running. Wait and try again or run a new task with
execute command enabled and try again.
まとめ
再起動ポリシーを使って、終了したコンテナの再起動を試してみました。タスクの置き換えよりは多少なりとも早く回復させることができそうなので、とりあえず有効にしておくのもありかもしれません。
冒頭にも書きましたが、あくまで終了したコンテナを再起動する仕組みですので、応答性が落ちているケースや、ハングしているようなケースは回復させられません。ヘルスチェックによるモニタリングも併用する必要があるでしょう。
最後に・・・
この投稿は個人的なものであり、所属組織を代表するものではありません。ご了承ください。