2023年3月に「Application Auto Scaling がターゲット追跡ポリシーに対する Metric Math に対応」というアップデートがありました。こちらを使うことで以前課題となっていた、CodeDeploy による ECS Blue/Green デプロイ環境下でのリクエストカウント追跡のオートスケーリングをシンプルに実現できそうだったので試してみました。
(検証用に作成した CDK コードなどは GitHub にあります。)
前提知識
そもそも、CodeDeploy で ECS Blue/Green を利用している際にリクエストカウント追跡によるオートスケーリングはただ設定するだけではうまく動作させることができませんでした。そのため、CodeDeploy のライフサイクルイベントフックで Lambda を実行してオートスケーリング設定 (ポリシー) を新しい Target Group に付け替えるという方法が一例としてありました。このあたりの CodeDeploy による ECS Blue/Green の挙動といった背景や Lambda の実装例については過去のブログを参照くださいませ。
前提知識 (2) Blue / Green デプロイの考慮事項
ドキュメントでは ECS サービスのオートスケーリングと B/G デプロイの併用は状況によってデプロイが失敗するケースがあると説明されています。あらかじめご承知を。
サービスの自動スケーリングと ブルー/グリーンデプロイタイプを使用するように設定されたサービスでは、自動スケーリングはデプロイ中にブロックされませんが、状況によってはデプロイが失敗する場合があります。以下では、この動作について詳しく説明します。
- サービスがスケーリングされていて、デプロイが開始されると、グリーンタスクセットが作成され、グリーンタスクセット CodeDeploy が定常状態になるまで最大 1 時間待機し、トラフィックが定常状態になるまでシフトしません。
- サービスが ブルー/グリーンデプロイのプロセス中で、スケーリングイベントが発生した場合、トラフィックは 5 分間シフトし続けます。サービスが 5 分以内に定常状態にならない CodeDeploy 場合、デプロイを停止し、失敗としてマークします。
Metric Math を使ったターゲット追跡ポリシー
Metric Math とは
Metric Math とは詳細はドキュメントを見ていただければと思いますが、簡単に言うと 1つ以上のメトリクスに対して数式を使って作成したメトリクスです。ドキュメントの例をそのままあげると、Lambda のメトリクスである Errors メトリクスを Invocations メトリクスで除算すると、エラー率を表すメトリクスを作ることができます。IF 式、検索式などいろいろあるので意外な使い方があるかもしれません。
冒頭で紹介したアップデートはこの Metric Math が Application Auto Scaling のターゲット追跡ポリシーに利用できるようになった、というものです。ドキュメントはこちら。
(ちなみに念の為ですが、ECS タスクのオートスケーリングは Application Auto Scaling によって実現されています。)
リクエストカウントメトリクスへの応用
そもそも ECS のマネジメントコンソールから設定できるターゲットあたりのリクエストカウント追跡のオートスケーリングは特定の 1つの Target Group についてのメトリクスを参照するため、CodeDeploy による B/G デプロイのように 2つの Target Group を使用する場合、他方の Target Group のメトリクスが考慮されません (スケーリングポリシーを自動で付け替えてくれたりはしません)、というものでした。
![]()
そこで Metric Math として、B/G デプロイの 2つの Target Group のリクエストカウントの合計を定義します。
(Target Group 1 のターゲットあたりのリクエストカウント) + (Target Group 2 のターゲットあたりのリクエストカウント)
合計してしまうとメトリクスとして相応しくないような気もしてしまいますが、ECS の B/G デプロイの場合、どちらか 1つの Target Group にしかリクエストは送信されないので、実質的に “どちらかの Target Group のターゲットあたりのリクエストカウントを表現するメトリクス” とみなすことができそうです。
![]()
Metric Math を使ったオートスケーリングの設定方法
(※ ECS サービス、CodeDeploy による B/G デプロイが設定済みである前提です)
マネジメントコンソールからは設定できないので、CLI から設定する必要があります。
まず Application Auto Scaling に対象の ECS サービスを登録します。
|
|
- 4行目 :
CLUSTER_NAMEとSERVICE_NAMEは ECS クラスターの名前とサービスの名前です - 5, 6行目 : 最小キャパシティを 1、最大キャパシティを 10としました
続いて、スケーリングポリシーを設定します。
|
|
- 7行目 :
file://configuration.jsonのところで、具体的なスケーリングの設定や参照するメトリクスを記述します。今回は以下のような JSON にしました。
|
|
- 2行目 : 1分あたりのターゲットあたりのリクエスト数が 500に収まるように設定しました
- 3行目 : スケールインのクールダウンタイムとして 120秒を設定しました
- 16, 34行目 : Target Group のフルネーム(?) を設定します。arn の
targetgroup/.../...の部分です - 45行目 : ここで数式を設定します。今回は 2つの Target Group の
RequestCountPerTargetの合計とします
(参考) CDK の場合
CDK ではまだ CloudFormation が対応していないこともあり、Constructor などは提供されていないようです。
そのため、現時点で CDK で設定したい場合は Custom Resource を利用します (Lambda なしでできます)。CDK での実装例は GitHub にありますので気になる方はご参照ください。
設定の確認
CLI でももちろん確認できますが、ここではマネジメントコンソールの CloudWatch Alarm から見てみます。
まずはスケールアウト用のアラーム (...-AlarmHigh-...)
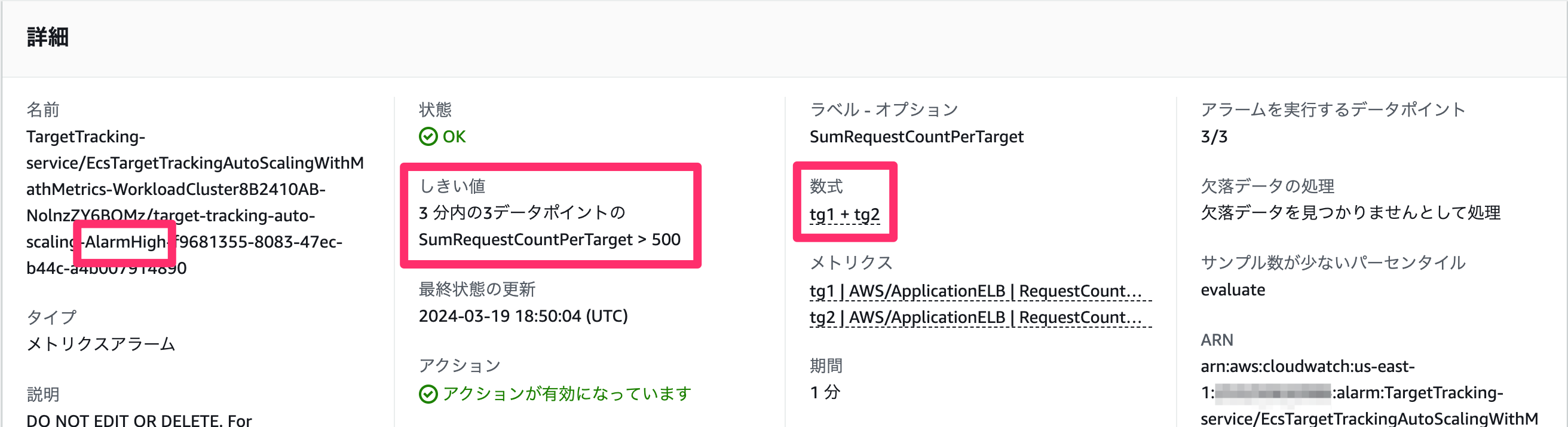 数式ベースでアラームが設定されています。3分間閾値を超え続けるとアラーム状態、つまりはスケールアウトが発動するようです。
数式ベースでアラームが設定されています。3分間閾値を超え続けるとアラーム状態、つまりはスケールアウトが発動するようです。
スケールイン用のアラームも見てみます。(...-AlarmLow-...)
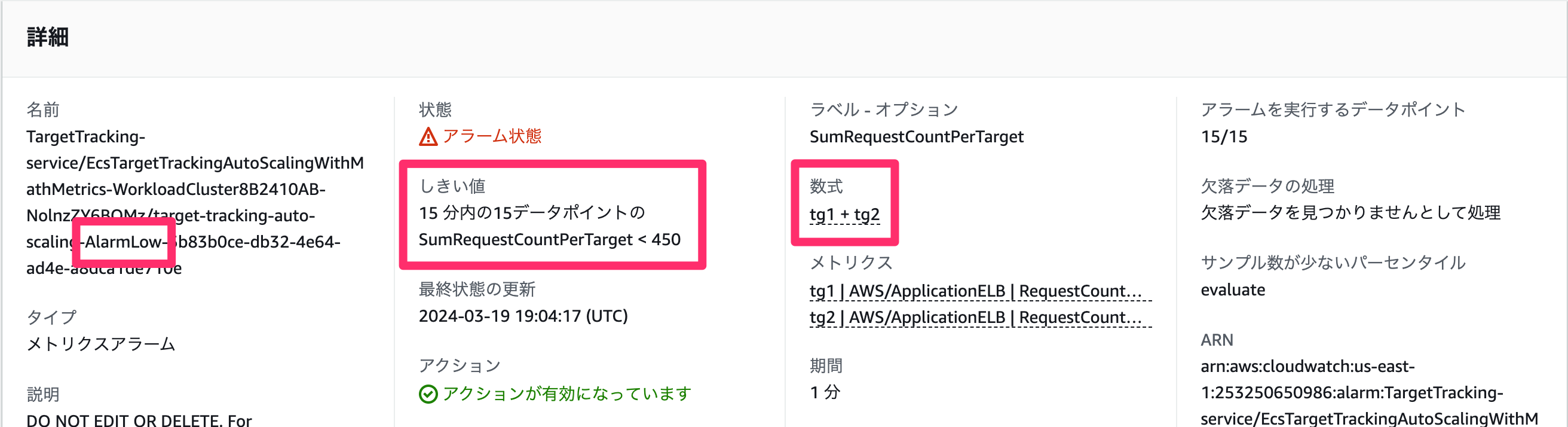 スケールアウトが 3分間の閾値超えで発動だったのに対して、スケールインは 15分間、(スケールアウト用の)閾値の 90% を下回り続けると発動します。
スケールアウトが 3分間の閾値超えで発動だったのに対して、スケールインは 15分間、(スケールアウト用の)閾値の 90% を下回り続けると発動します。
ドキュメントには「考慮事項」や「制限事項」についても記載があるので、一読しておくと良いと思います。
負荷を上げながら B/G デプロイを実行してみる
では実際に負荷をかけて、うまくスケールするか確認してみたいと思います。拙いコードで恐縮ですが、ab コマンドを使って以下のコードで負荷をかけていきました。スケーリングイベントとしてアウトもインも発生させたいので、負荷は徐々に上げた後、同じように徐々に下げていきます。この負荷をかけながら、途中で B/G デプロイを実行してみます。
以前の CodeDeploy のライフサイクルイベントフックの例では、B/G デプロイ中はオートスケーリングポリシーを外す実装例で紹介しましたが、今回はポリシーを付けたまま実行してみます。
|
|
実行結果
実行した結果のメトリクスを見てみます。
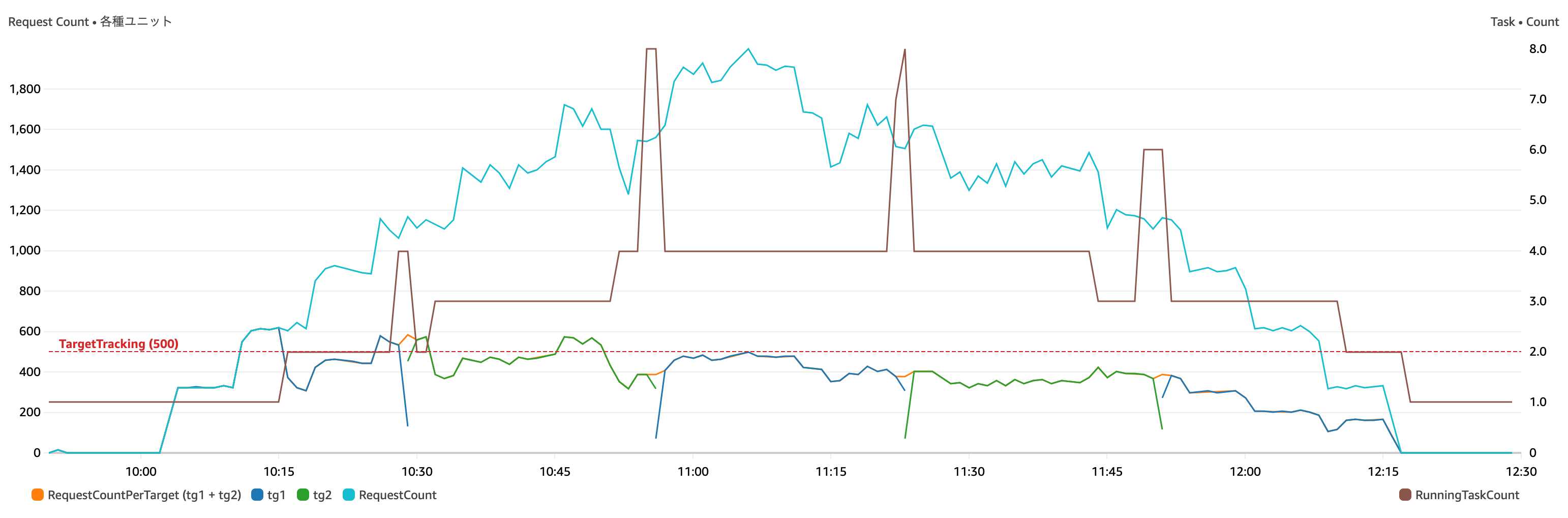
(メトリクスの “期間” は全て 1分)
左側の Y 軸
- 水色 : 負荷の総リクエスト数。ALB の
RequestCountの合計 - 濃い青 : Target Group 1の
RequestCountPerTargetの合計 - 濃い緑 : Target Group 2の
RequestCountPerTargetの合計 - オレンジ : Target Group 1、2の
RequestCountPerTargetの合計 (このメトリクスでターゲット追跡ポリシーを設定) - 赤色の水平点線 : ターゲット追跡する値 (今回は 500で設定)
右側の Y 軸
- 茶色 : 実行中のタスク数の最大数 (Container Insights の
RunningTaskCount)
少々グラフが多くて見辛いかもしれないので、簡単に説明を。
水色の線が負荷 (ALB の RequestCount) で、前述のスクリプトの通り徐々に同時リクエスト数を増やして負荷を上げています。その後、スケールイン時の動作も見たかったので徐々に負荷を下げていきます。
濃い青色と緑色のグラフの間を結ぶようにオレンジ色のグラフが少しだけ見えていますが、このオレンジ色の線が Target Group 1, 2 それぞれの RequestCountPerTarget を Metric Math として合計した値のグラフになります。青や緑が重なってしまって少ししか見えていませんが、実際には連続して繋がったグラフになります。この値にターゲット追跡のスケーリングポリシーを適用していきます。このオレンジのグラフが赤色の水平点線を超え続けるとスケールアウトが発動されるというわけです。
右の Y 軸のメトリクスである、RunningTaskCount では 4箇所ほどスパイクしている箇所があります。ここで Blue/Green デプロイを実行していますのでタスクセットが一時的に2つに、すなわちタスク数が Blue 環境と Green 環境を合わせた数になっています。実際は Green 環境でテストしたりするので Green 環境の寿命はもっと長い (タスク数が2倍になっている期間がもっと長い) かと思いますが、今回はすぐに切り替えを行なっています。
ざっと見た感じ、うまくスケールアウト / インできていそうです。ab コマンドの結果の Failed requests も全て 0 でした (このあたりはコンテナで実行しているワークロードによって変わってくるかもしれませんのでご参考程度に)。
デプロイ中にスケールイベントが発生した場合
前述の B/G デプロイでは Blue と Green の切り替えをすぐに実行してみた結果でした。では Green 環境がテスト用にデプロイされている間にスケールイベントが発生したらどうなるのか気になりました。Blue 側だけスケールアウトして、いざ切り替えた時に Green 側でキャパシティが十分でないと困りますよね。
というわけで Green 環境作成後、Blue と Green の切り替えを行わずに負荷を上げ続けスケールイベントを発生させてみました。下の図はそのメトリクスです。
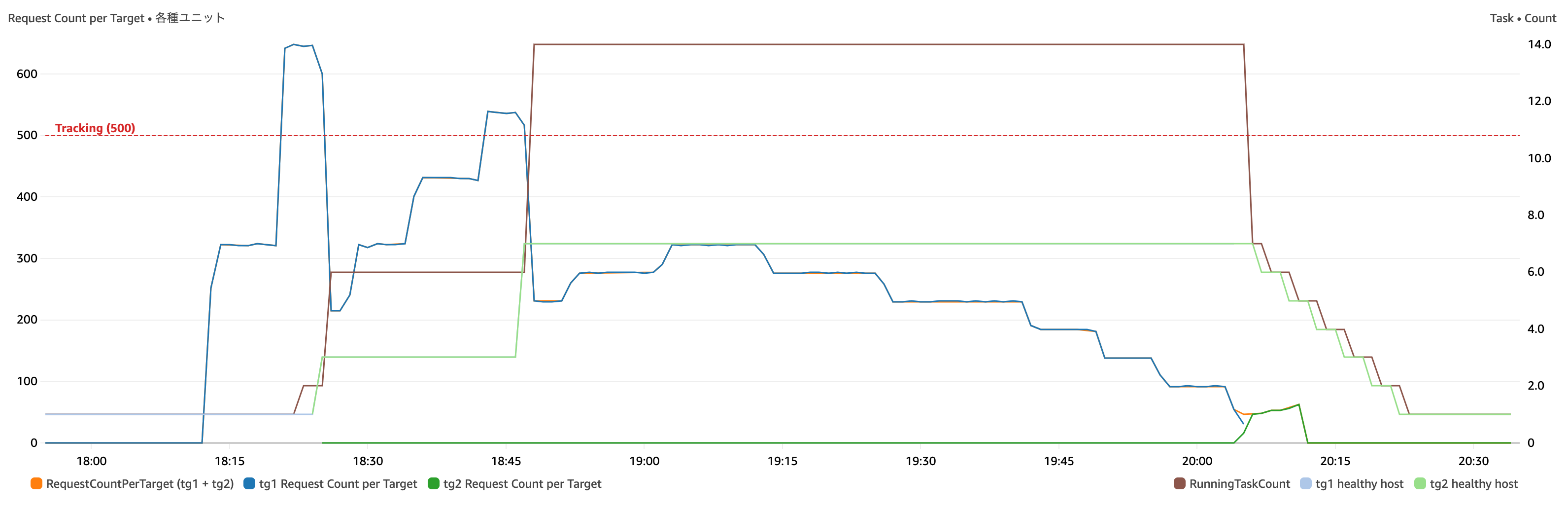
(メトリクスの “期間” は全て 1分)
20:05 ぐらいのタイミングで B/G の切り替え (“トラフィックの再ルーティング”)を実行しています。
左側の Y 軸
- 濃い青 : Target Group 1の
RequestCountPerTargetの合計 - 濃い緑 : Target Group 2の
RequestCountPerTargetの合計 (※切り替えを行なっていないので ~ 20:05 ぐらいまで 0 のままです) - オレンジ : Target Group 1、2の
RequestCountPerTargetの合計 (※濃い青と重なっているのでほとんど見えていません) - 赤色の水平点線 : ターゲット追跡する値 (今回は 500で設定)
右側の Y 軸 (期間は全て 1分)
- 薄い水色 : Target Group 1の
HealthyHostCountの平均を使って、起動中のタスク数と見立てています - 薄い緑色 : Target Group 2の
HealthyHostCountの平均を使って、起動中のタスク数と見立てています - 茶色 : 実行中のタスク数の最大数 (Container Insights の
RunningTaskCount)
濃い青色である Target Group 1 の RequestCountPerTarget がターゲット追跡値である赤色の水平点線を超え続けるとスケールアウトが発生します (上図では、18:25、18:47 あたりの 2回発生しています)。
負荷上昇時
上図ではちょっとわかりにくいのですが、負荷が上昇しスケールアウトが実行されると、下図の通り Blue 側と Green 側の両方でタスクが追加されます (茶色の RunningTaskCount は Blue 環境と Green 環境のタスク数の合計)。
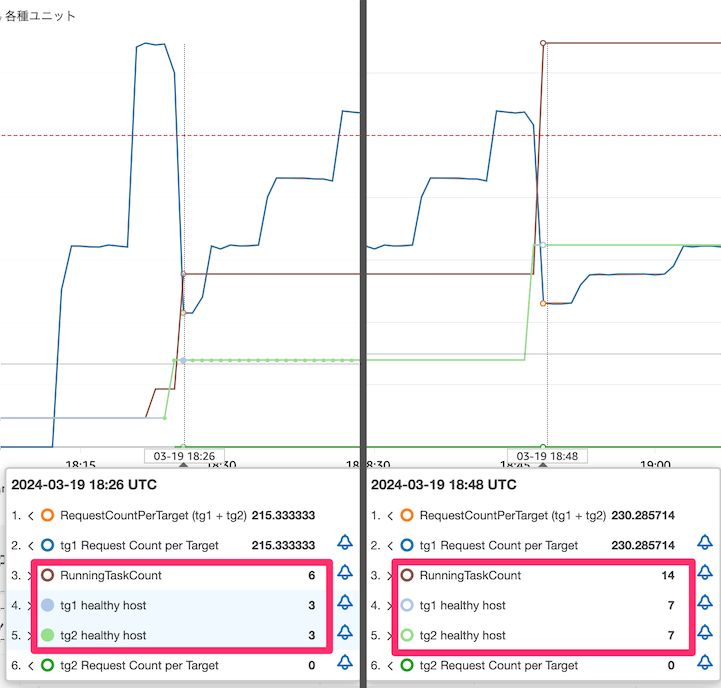
tg1 healthy host と tg2 healthy host の値が同じ数になっています
負荷減少時
一方、B/G デプロイ中の場合、負荷が下がっていっている状況下ではスケールインが発動しません。B/G デプロイの切り替えが完了するとスケールインが開始されました。
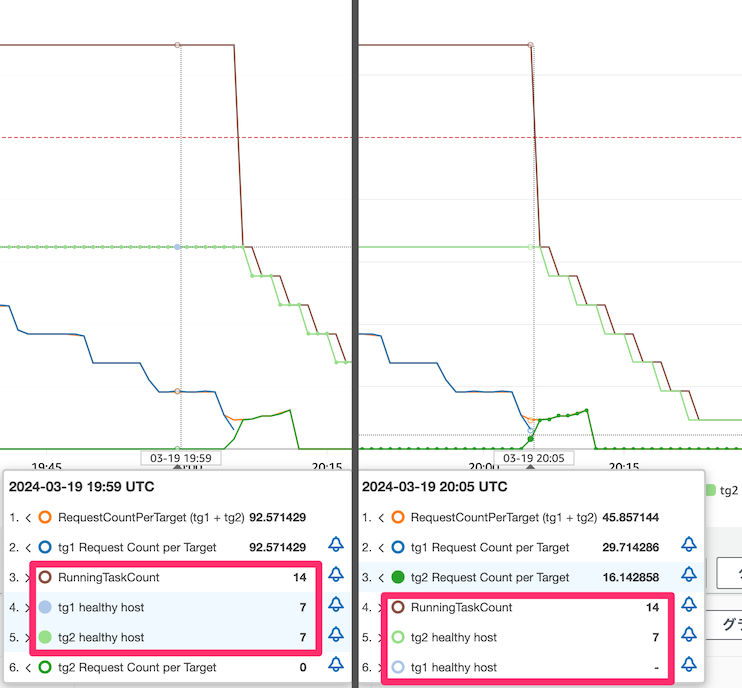
(左側) スケールインのターゲット追跡の値が 450 (= 500 x 90%) であるにも関わらず、RequestCountPerTarget が 90 近くになってもスケールインは発動していません
(右側) 切り替え (“トラフィックの再ルーティング"を実行) 後にスケールインが発動されています
負荷上昇時は Blue 環境にあわせて Green 環境のタスクセットも同等にスケールアウトされますが、負荷減少時のスケールインは Blue 環境も Green 環境も抑制されていました。 よりフェイルセーフな考え方になっていそうです。
B/G 切り替え後、タスク数が足りないといったことは問題にならなさそうですが、一方でスケールアウトしたタスクがスケールインしないということなのでテスト期間が長い (Green 環境の寿命が長い) とその分、タスク数としてはピーク状態の 2倍起動したままになるのでコストが上乗せになる点に注意が必要そうです。
まとめ
ECS サービスで CodeDeploy の Blue / Green デプロイ利用時に、Target Group のリクエストカウントでターゲット追跡のオートスケーリングに Metric Math を活用して試してみました。
Blue、Green それぞの Target Group のメトリクスを Metric Math として合算し、この値でターゲット追跡のオートスケーリングポリシーを設定することで、ポリシーの付け替えなしで実現することができました。試してみた範囲ではうまく動いたのではないかと思います。
実際に利用する場合は、十分に検証の上ご利用ください。
最後に・・・
この投稿は個人的なものであり、所属組織を代表するものではありません。ご了承ください。