レガシーなシステムとの連携のために DynamoDB テーブルの内容を CSV に出力したいという要件、まあまああるのではないかなと思います。そもそもその CSV 連携をやめてもっと効率の良いやり方で、、、と言いたくなるところではありますが、しがらみの多い世界だとそうもいきません。一方で、CSV 出力のために稼働中の DynamoDB テーブルに対して全件スキャンとかもキャパシティのことを考えるとしたくないものです。
2020年11月に DynamoDB テーブルデータを Amazon S3 のデータレイクにエクスポート する機能が発表されました。この機能を使って、キャパシティを消費することなく CSV 出力し、さらに Step Functions で自動化を実現する機会がありましたのでメモとして残しておきたいと思います。
従来からの一般的な方式
今回利用する “DynamoDB テーブルデータを S3 にエクスポートする” 機能が出る以前では クラスメソッドさんでも紹介されているような、Glue を使って DynamoDB テーブルからデータをロードし、CSV ファイルとして出力していく方法が一般的な方式でした。
従来方式での課題
従来の方式でも全く問題はないのですが、以下のケースで課題、、、とまではいかなくてもちょっと二の足を踏んでしまうケースがあります。
- Glue を利用する上で必要な、PySpark や Python に慣れていない(使ったことない)
- DynamoDB の RCU (Read Capacity Unit) を極力消費したくない
- 接続パラメータ
dynamodb.throughput.read.percentを利用して Glue から DynamoDB テーブル読み取り時のキャパシティを調整することができますが、DynamoDB テーブルのキャパシティモードがプロビジョンドキャパシティである場合に限られます(オンデマンドキャパシティの場合、この接続パラメータは効きません)。
- 接続パラメータ
Glue (PySpark) を使わず、また DynamoDB の RCU を消費しない方式で CSV 出力を実現したいと思います。
新機能を使った方式(ざっくりとした方針)
DynamoDB のテーブルデータを S3 にエクスポートすると、DynamoDB JSON 形式または Amazon Ion 形式で出力することができます(S3 には複数のファイルで出力されます)。このファイルをソースに Athena を使ってテーブルを作成し、そのテーブルに同じく Athena から select クエリを実行することで、結果が S3 に CSV として出力されますのでこちらを利用します。
アーキテクチャ
ベースとなるアーキテクチャは以下になります。

Step Functions による自動化
今回はこの CSV 出力を定期的に実行させるため、Event Bride と Step Functions を利用し、以下のようなアーキテクチャで実現しました。こちらは AWS SAM (Serverless Application Model) で GitHub に実装例としてあげておきました。
GitHub : https://github.com/msysh/aws-sample-sam-ddb2csv
※本サンプルは、自己責任の範囲でご利用ください。

ベース部分の解説
自動化する前のベースとなるアーキテクチャについて解説したいと思います。
前提条件
まず前提条件として以下を確認してください。
- 対象の DynamoDB テーブルでポイントインタイムリカバリを有効化しておく必要があります
- 出力される CSV の各項目はダブルクォーテーション(
")で括られます
DynamoDB からのエクスポート
DynamoDB テーブルの “エクスポートおよびストリーム” タブから “S3 へのエクスポート” を選択し、出力先となる S3 バケットの情報などを入力します。最終的な出力先は s3://<バケット名>/<プレフィックス>/AWSDynamoDB/<エクスポートID>/ となります。
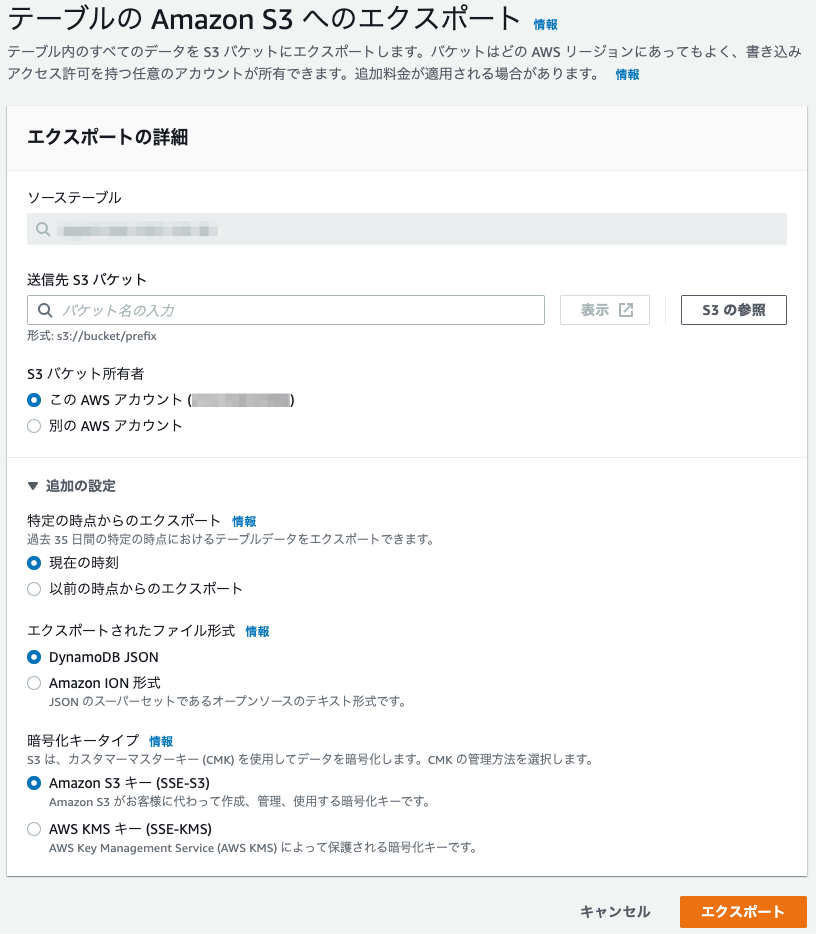
エクスポートのジョブが一覧として表示されます。“状態” が、下図のようにEXPORT_完了になったら完了です。CLI などからエクスポートのステータスを確認したい場合は aws dynamodb describe-export --export-arn <赤枠の Export ARN>で見れます。

エクスポート結果
エクスポートが完了すると、s3://<バケット名>/<プレフィックス>/AWSDynamoDB/<エクスポートID>/に以下のように出力されます。マニフェストファイルなどは今回は利用しません。data/の中に、実際に出力されたデータが入っています。
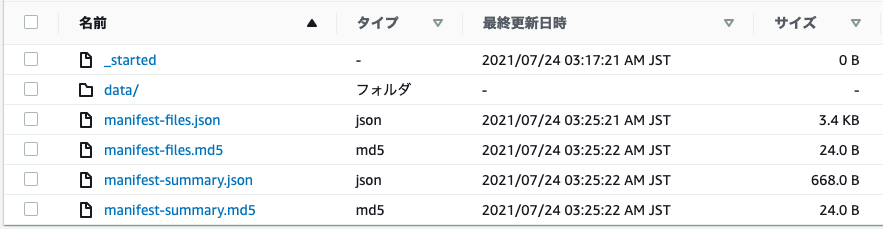
以下の図はdata/の中です。ファイルは複数ファイルに出力され、ファイルサイズもまちまちです。
ファイルの中身は “DynamoDB JSON” という形式になっており、テーブルの1アイテムは例えば、以下のような形式になります(読みやすく改行、インデントしています)。実物は JSON Lines という 1 アイテム 1 行で、複数アイテム、すなわち複数行になっており、かつ gzip 形式で圧縮されています。
DynamoDB JSON については ドキュメント も参考になります。
(以下サンプルの “id” や “field0” などはテーブルのカラム名です。)
{
"Item":{
"id":{
"S": "id-1"
},
"field0":{
"S": "value-00"
},
"field1":{
"S": "value-01"
},
"field2":{
"S": "value-02"
},
"field3":{
"S": "value-03"
},
"field4":{
"S": "value-04"
}
}
}
Athena からテーブル作成
出力された JSON データを元にテーブルを作成します。以下のクエリでテーブルを作成します。
※ Athena を利用する上での初期セットアップが完了していない場合は、ドキュメントのステップ1を実施しておきます。
(“id” や “field0” などはテーブルのカラム名です。)
CREATE EXTERNAL TABLE IF NOT EXISTS
<データベース名>.<テーブル名> (
Item struct <
id:struct<S:string>,
field0:struct<S:string>,
field1:struct<S:string>,
field2:struct<S:string>,
field3:struct<S:string>,
field4:struct<S:string>
>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://<バケット名>/<プレフィックス>/AWSDynamoDB/<エクスポートID>/data/'
TBLPROPERTIES ('has_encrypted_data'='true')
テーブルへのクエリ
続いて、テーブルに対してクエリをかけていきます。ソートして CSV 出力、フィルタして CSV 出力したい場合は SQL で指定します。今回はパーティションキーでソートしました。
SELECT
Item.id.S as id,
Item.field0.S as field0,
Item.field1.S as field1,
Item.field2.S as field2,
Item.field3.S as field3,
Item.field4.S as field4
FROM
<データベース名>.<テーブル名>
ORDER BY
Item.id.S
クエリ結果のファイル
Athena でクエリを実行するとマネジメントコンソール上で結果を表形式で見ることができますが、実は CSV ファイルとしても出力されており(ドキュメント)、この CSV を利用するというわけです。
自動化
今回は、DynamoDB テーブルの CSV 出力を定期的に行いたい、という要件でしたので、一連のワークフローを Step Functions で定義し、EventBridge からスケジュール起動するような方式にしました。以下は Step Functions ステートマシンのグラフです。
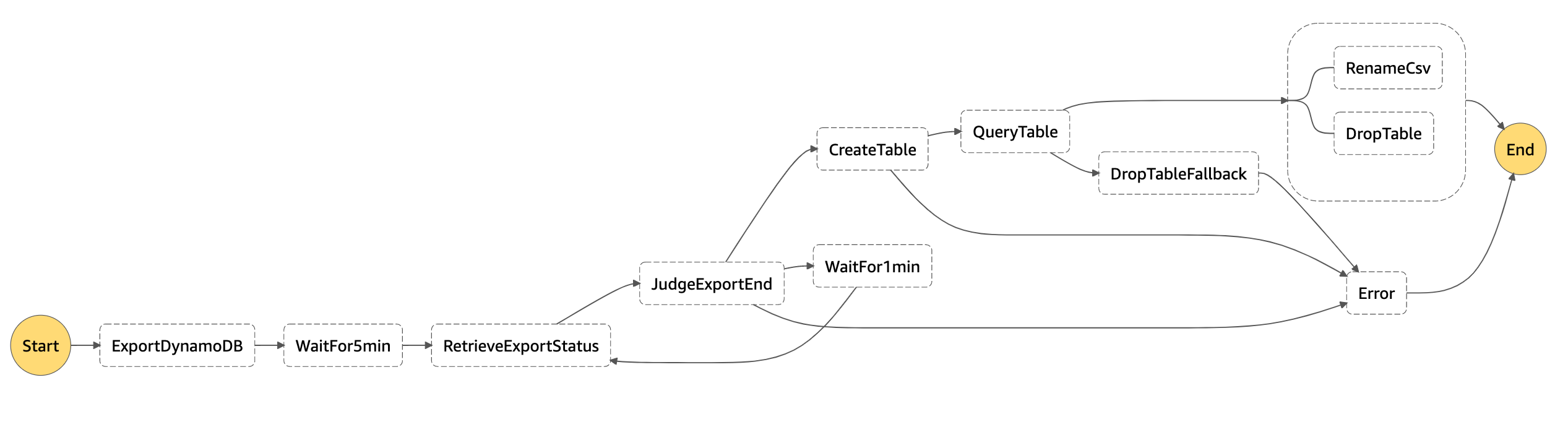
各ステートについて
- ExportDynamoDB
- Lambda から DynamoDB の
ExportTableToPointInTimeAPI を呼び出します。
- Lambda から DynamoDB の
- WaitFor5min
- エクスポートには時間がかかるので
Waitタイプのステートを使って、一旦、5分程度待ちます(私が検証した範囲では、データがほとんどなくてもエクスポート完了までに 5分程度かかりました)。
- エクスポートには時間がかかるので
- RetrieveExportStatus
- Lambda から DynamoDB の
DescribeExportAPI を呼び出し、エクスポートが完了しているか問い合わせます。
- Lambda から DynamoDB の
- JudgeExportEnd
- エクスポートが完了しているかどうか
Choiceタイプのステートを使って判定します。
- エクスポートが完了しているかどうか
- WaitFor1min
- エクスポートが完了していなかった場合は、
Waitタイプのステートを使って追加で1分ほど待ちます。その後再度RetrieveExportStatusステートを実行します。
- エクスポートが完了していなかった場合は、
- CreateTable
- エクスポートが完了したら、Athena の
startQueryExecutionタスクで 前述の create table を実行します。Resourceには末尾に.syncを付けて同期的に実行するようにしています。
- エクスポートが完了したら、Athena の
- QueryTable
- 作成されたテーブルに対して select クエリを実行します。
Resourceには末尾に.syncを付けて同期的に実行するようにしています。クエリ結果である単一の CSV ファイルが S3 バケットに出力されます。
- 作成されたテーブルに対して select クエリを実行します。
- DropTableFallback
- クエリの実行に失敗した場合のテーブル削除処理です。
- RenameCSV
- 今回の要件では CSV ファイルの S3 プレフィックス、ファイル名を特定のものにしつつ、gzip で圧縮したいという要件もありましたので、Lambda で実装しています。rename (move) ができる API はないので、コピー & 削除で実現しています。
- 大きなファイルサイズの CSV の圧縮にも対応するためストリームを使って処理しています(12 GB 程度の CSV まで確認済み)。
UPLOADAPI のqueueSize(並列度)、、などを上げることで大きなファイルサイズにも対応できるのではないかと思います(12GB 以上は未確認です)。
- DropTable
- 定期的に実行する処理としているため、クエリの実行完了後はテーブルを削除しています。
- Error
- 何らかのエラーが発生した場合は、ここでキャッチするようにし「失敗」としてマークします。
実装サンプル
冒頭の通り、Event Bride と Step Functions を利用して、AWS SAM (Serverless Application Model) でデプロイできるようにしました。
GitHub (msysh/aws-sample-sam-ddb2csv)
コンポーネント
GitHub の README にも書いていますが、以下のもので構成されています。
- lambda-export-ddb :
- PITR(Point in Time Recovery)を使用して DynamoDB テーブルから DynamoDB JSON をエクスポートする Lambda 関数のコード
- lambda-rename-compress-csv :
- エクスポートされた CSV ファイルの名前を変更して GZIP 圧縮する Lambda 関数のコード(Python で「ストリームで圧縮」というのができるのかどうかわからなかったので この Lambda だけ JavaScript で実装です…)
- lambda-rename-csv :
- エクスポートされた CSV ファイルの名前を変更するだけの Lambda 関数のコード(S3 で「リネーム」はできないので copy & delete しています)
- lambda-retrieve-status :
- エクスポートステータス(進捗状況)を取得する Lambda 関数のコード
- statemachine :
- Step Functions の定義ファイル(Amazon States Language)のコード
- template.yaml :
- AWS リソースを定義した SAM テンプレート
デプロイ方法
AWS SAM をインストールして、以下を実行します。
sam build --use-container
sam deploy --guided
2番目のコマンドを実行すると、いろいろとパラメータの設定値を聞かれますので入力していきます。
- Stack Name : CloudFormation でデプロイするスタック名で、アカウントとリージョンで一意にする必要があります。
パラメータ :
| パラメータ名 | 説明 | デフォルト値 |
|---|---|---|
| DynamoDBTableName | エクスポート対象の DynamoDB テーブル名 | table-name |
| DynamoDBSchema | Athena での CREATE TABLE 時に指定するカラム定義(デフォルト値は DynamoDB テーブルに “pk”, “field0”, “field1” という文字列型のカラムがあるイメージ) |
pk:struct<S:string>,field0:struct<S:string>,field1:struct<N:string> |
| ExportS3Bucket | エクスポートされた JSON ファイルの出力先となる S3 バケット名 | your-bucket |
| ExportS3Prefix | エクスポートされた JSON ファイルの出力先となる S3 バケットのプレフィックス | dynamodb/export |
| OutputCsvS3Bucket | Athena からのクエリ結果を出力する S3 バケット | your-bucket |
| OutputCsvS3Prefix | Athena からのクエリ結果を出力する S3 バケットのプレフィックス | ddb2csv |
| RenameCsvS3Bucket | Athena から出力された CSV ファイルのリネーム後の S3 バケット | your-bucket |
| RenameCsvS3PrefixFormat | Athena から出力された CSV ファイルのリネーム後の S3 バケットのプレフィックスで strftime フォーマットが利用可能 |
dst/%Y/%m/%d/%H |
| RenameCsvTimezoneForPrefixFormat | 上記 strftime フォーマットで指定するタイムゾーン(例 : Asia/Tokyo) |
UTC |
| RenameCsvFileName | リネーム後の CSV ファイル名 | exported.csv |
| CompressCsv | リネーム後の CSV ファイルを圧縮するかどうか | false |
| AthenaDatabase | Athena のデータベース名 | default |
| AthenaTemporaryTable | Athena でテーブルを作成する際のテーブル名. このテーブルは Step Functions 実行の都度、削除されます | ddb2csb_exported |
| AthenaQueryFields | Athena で SELECT クエリする際のカラム指定 |
Item.pk.S as pk, Item.field0.S as field0, Item.field1.N as field1 |
| LogLevel | Lambda (Python) のログレベル指定 (DEBUG, INFO, WARNING, ERROR, CRITICAL) | WARNING |
その他、SAM 関連のパラメータ :
- Confirm changes before deploy: 「yes」に設定すると、実行前に変更セットが表示され確認できます。「no」にすると確認なしでデプロイまで実行します。
- Allow SAM CLI IAM role creation: 必要な IAM Role の作成を許可するために、
CAPABILITY_IAMを設定します。これはsam deploy時に、--capabilities CAPABILITY_IAMを指定することと同じです。 - Save arguments to samconfig.toml: 「yes」に設定すると、選択内容がプロジェクト内の構成ファイル(
samconfig.toml)に保存され、次回以降sam deployをパラメーターなしで再実行できます。
定期実行させたい場合
SAM テンプレート内に Step Functions をスケジュール実行するための設定が入っていますが、無効化しています。
Schedule で実行タイミング、頻度を指定し、Enabledにtrueを設定してデプロイすると有効化されます。
(Schedule の書き方はドキュメントをご参照ください)
|
|
Athena からのクエリを変更したい場合
Athena からの select 実行時に join したい、where 句書きたい、といった場合には Step Functions の QueryTable タスクの QueryString を変更してください。
GitHub (statemachine/ddb2csv.asl.json)
|
|
CSV ファイル圧縮のチューニング
S3 へのアップロード処理(コピー処理)でキュー(queueSize、並列度)を増やす、Lambda のメモリも大きくするなどして試してみてください。
サンプルでは以下のように設定しています。
queueSize: 2(SDK のデフォルトは 1)- Lambda のメモリ : 2048 MB
queueSizeの指定
コード内では UPLOAD_CONCURRENCY という定数に設定しています。
GitHub (ambda-rename-compress-csv/app.js)
|
|
|
|
Lambda のメモリサイズ指定
|
|
その他の考慮点
サンプルでは実装していませんが、実際には以下などについても考慮が必要になってくるかなと思います。
- S3 ライフサイクル設定
- DynamoDB からエクスポートされた JSON ファイルの定期的な削除
- Step Functions でのエラー時の処理
- エラーが発生したら何らか通知できるように(知得できるように)しておきたいですね
- 監視とか
- Step Functions 実行メトリクスの
ExecutionTime,ExecutionsFailed,ExecutionAborted,ExecutionsSucceededとか - Step Functions サービスインテグレーションメトリクスの
startQueryExecution.syncのServiceIntegrationsFailedとか - Lambda の
Duration,Errorとか
- Step Functions 実行メトリクスの
削除
この SAM アプリを削除する場合は、マネジメントコンソールの CloudFormation からスタックを削除するか、以下のコマンドによりスタックを削除できます。
aws cloudformation delete-stack --stack-name <スタック名>
実行結果例
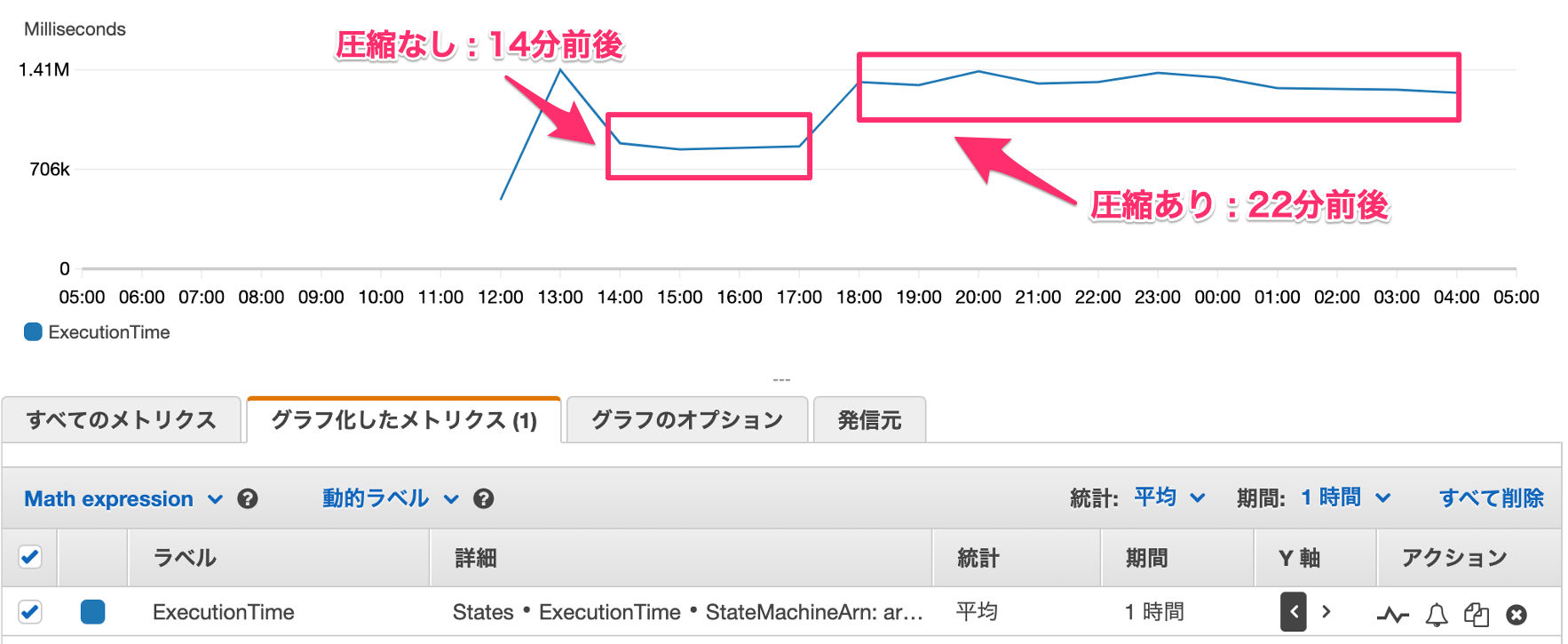
時間としてどの程度かかるか気になるところかと思いますので、2021年3月ごろに以下の条件で実行してみました。あくまで参考値としてご理解ください。
- データ件数 : 10,000,000 件
- テーブルサイズ : 約 9 GB
- 1 項目の平均サイズ : 904.88 バイト
- 利用リージョン : us-east-1(バージニア北部)
- 出力した CSV ファイルの GZIP「圧縮なし」と「圧縮あり」の2パターン

Step Functions の実行時間としては以下のようになりました。
- 圧縮なし : 14分前後
- 圧縮あり : 22分前後
以下は、1時間おきに実行した場合の Step Functions の ExecutionTime です。
まとめ
DynamoDB テーブルのデータを CSV で出力したい場合に DynamoDB のエクスポート機能と Athena の機能を使って、キャパシティを消費することなく実現してみました。また、Glue といった PySpark も利用しないので、Glue に対してハードルを感じていた方でも実現しやすいかと思います。
(とは言え、個人的にはできれば「CSV ファイルが必要な方式」そのものを見直していけるとより良いかなと思ったりします。。。)
最後に・・・
この投稿は個人的なものであり、所属組織を代表するものではありません。ご了承ください。
※本サンプルは、自己責任の範囲でご利用ください。